模型|继LSTM之父用世界模型来模拟2D赛车后,谷歌又推出全新世界模型助力导航:360度无死角,就问你怕了没?( 三 )
在具有高度不确定性的区域,比如拐角或视线以外的房间,可能会出现许多不同的场景。而Pathdreamer能够生成满足区域高度不确定的多样化结果。
有感于受到纽约大学Rob Fergus与Emily Denton提出的随机视频生成思想,Pathdreamer的结构生成器以噪音变量为条件,该变量表示指导图像中没有捕获的下一个导航位置的随机信息。通过对多个噪音变量进行采样,Pathdreamer可以合成多个不同场景,允许智能体在一条给定的导航路线中对多个合理的结果进行采样。
这些不同的输出不仅反映在第一阶段的输出(语义分割和深度图像)中,还反映在生成的 RGB 图像中。
如下图所示,最左侧的一列指导图像表示智能体先前看到的像素。其中,黑色像素表示智能体原先看不见的区域,对此,Pathdreamer 通过对多个随机噪声向量进行采样,生成了不同的图像输出。在实践中,当智能体在一个环境中定位导航时,它可以通过新的观察结果来生成输出图像。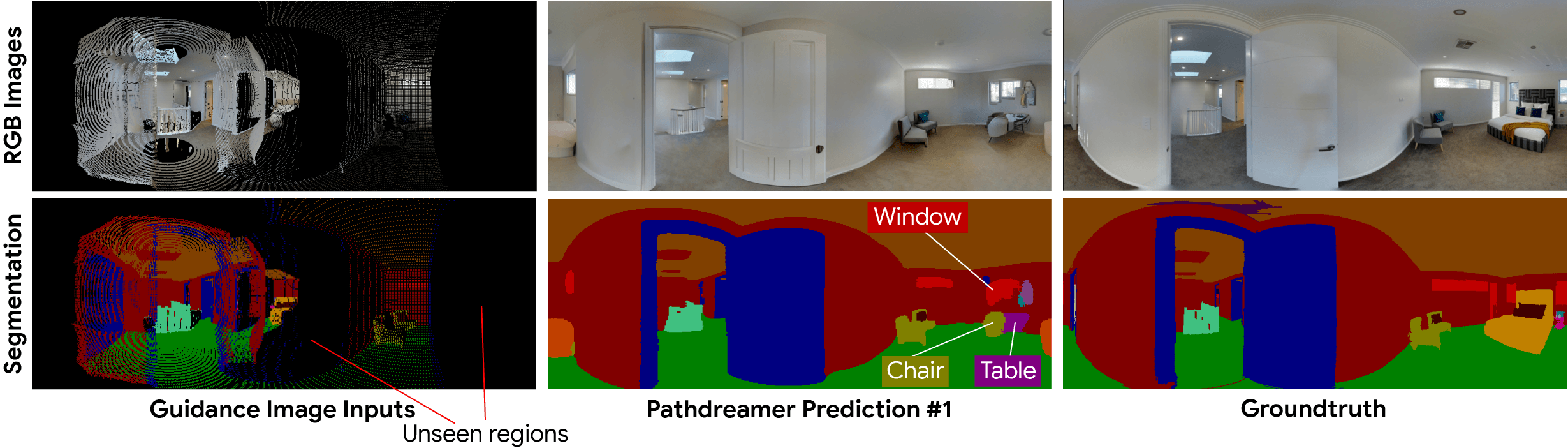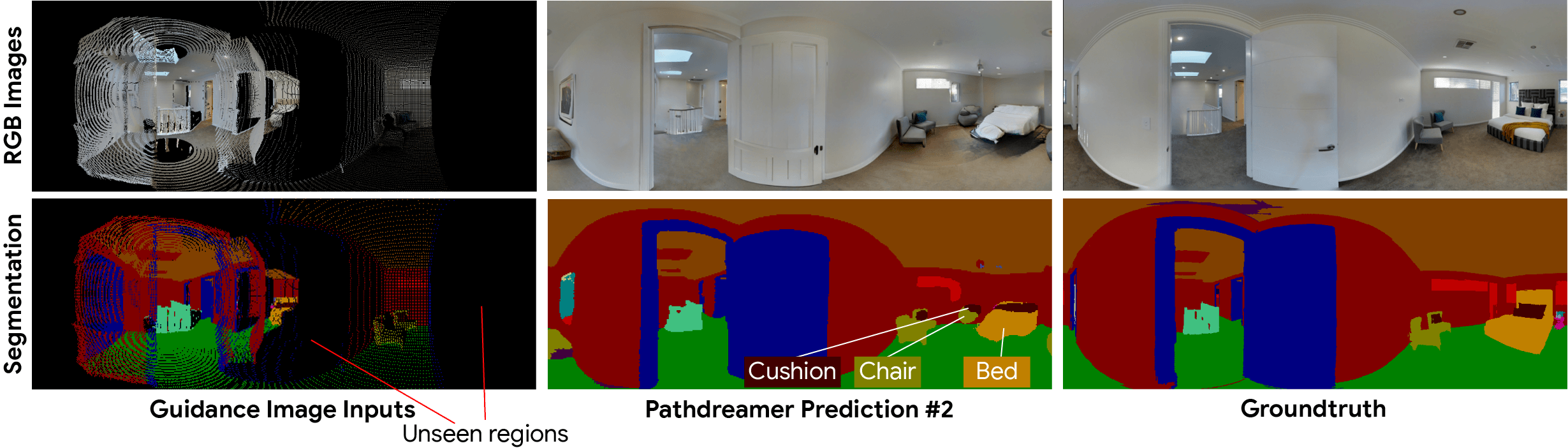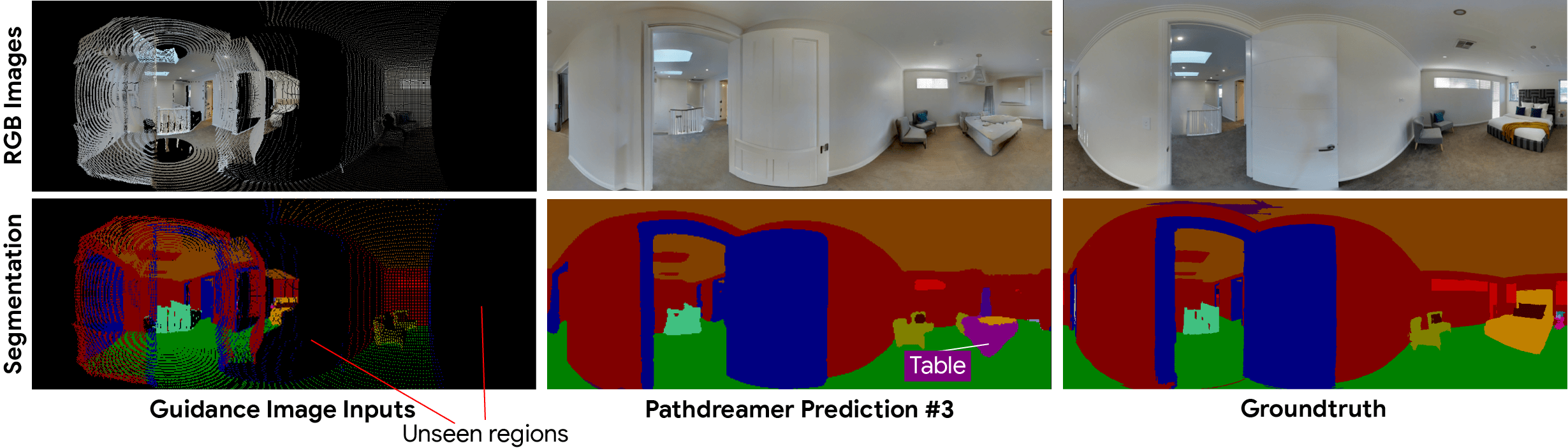
文章插图
Pathdreamer 基于来自 Matterport3D 的图像和 3D 环境重建进行训练,并且能够合成逼真的图像与连续的视频序列。由于输出图像具有高分辨率和 360o 无死角的特征,现有的导航机器人可以轻松地将图像转换,以适应机器人配有的相机视野。
4、将Pathdreamer应用于视觉导航任务
他们将 Pathdreamer 应用于视觉与语言导航 (VLN) 任务,其中,机器人必须遵循自然语言的指令定位到真实 3D 环境中的某一个位置。他们使用 Room-to-Room(R2R)数据集进行了一项实验,让指令机器人在模拟多条可能的行走轨迹前进行规划,并根据导航指令对每一条轨迹进行排名,然后选择排名第一的轨迹进行导航。
实验考虑了三种设置:
1)地面实况(ground truth)设置:机器人通过与真实的环境互动(比如移动)来进行规划;
2)基线(Baseline)设置:机器人提前规划,无需与导航图交互、对建筑内的导航路线进行编码,但没有提供任何视觉观察;
3)Pathdreamer 设置:机器人提前规划,无需与导航图交互,且还能接收到Pathdreamer所生成的对应视觉观察。
在Pathdreamer设置中,机器人提前三步(大约6米)规划,导航成功率高达 50.4%,而基线设置的成功率只有 40.6%。这表明,Pathdreamer对现实室内环境中的有用、且可以访问的视觉、空间与语义知识进行了编码。
而在地面实况的设置中,机器人通过移动进行规划,导航成功率达到了 59%。不过,地面实况设置要求机器人花费大量的时间与资源进行多轨迹探索,在现实世界中的代价可能十分高昂。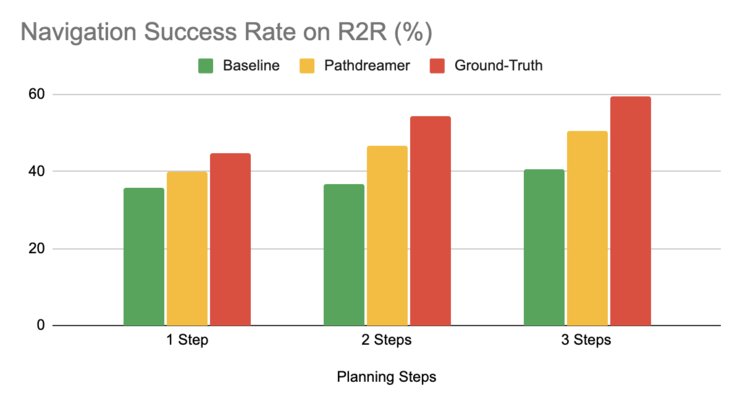
文章插图
图注:VLN机器人在三种设置(地面实况、基线与Pathdreamer)中的表现
实验结果表明,类似 Pathdreamer 的世界模型在处理复杂的导航任务中具有出色表现。
参考链接:
1、https://ai.googleblog.com/2021/09/pathdreamer-world-model-for-indoor.html
2、https://ai.facebook.com/blog/near-perfect-point-goal-navigation-from-25-billion-frames-of-experience/
3、https://ai.googleblog.com/2021/04/model-based-rl-for-decentralized-multi.html
4、https://ai.googleblog.com/2020/03/introducing-dreamer-scalable.html
5、https://worldmodels.github.io/
6、https://ai.googleblog.com/2021/02/mastering-atari-with-discrete-world.html
7、https://bair.berkeley.edu/blog/2019/12/12/mbpo/
【 模型|继LSTM之父用世界模型来模拟2D赛车后,谷歌又推出全新世界模型助力导航:360度无死角,就问你怕了没?】8、https://blog.csdn.net/hhy_csdn/article/details/88207977
- Java|Gamamobi CEO黄继德:我们的元宇宙游戏不担心体验落差
- 继华为nova10系列线下物料曝光后|华为nova 10真机上手图曝光:后摄神似“双星伴月”
- 联想|手机黑马真我GT2大师探索版 继小米12Ultra骁龙8gen1plus首发机型
- 显示器|刹不住车?爆腾讯下半年将继续大规模裁员
- 抖音|信号继电器如何分类? 信号继电器的工作原理及作用
- 5G|狂欢继续 嗨购不停 6月购三星Galaxy S21 FE 5G享好礼
- 奥拓电子|刹不住车?爆腾讯下半年将继续大规模裁员
- 从几个月到几分钟,NLP模型运行效率暴涨,小公司也能玩大模型
- 腾讯文档|从事展览3d模型设计,你需要具备那些能力?---模大狮网
- 电动自行车|iPhone14今年屏幕需求或超2.05亿块,京东方继续供货