物体|无需任何标记数据,几张照片就能还原出3D物体结构,自监督学习还能这样用( 二 )
在监督学习所用到的参数上,可用的包括深度、关键点、边界框、多视图4类;而在测试部分,则包括2D转3D、语义和场景3种方式。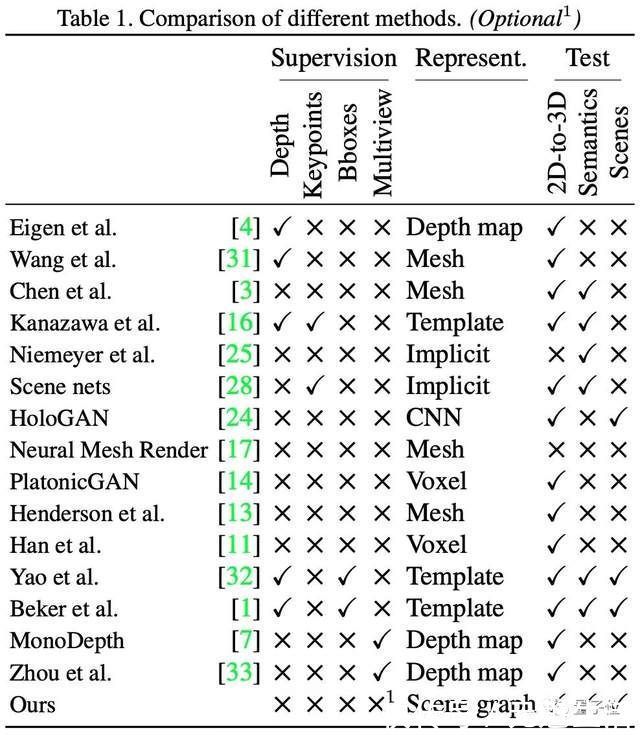
文章插图
可以看见,绝大多数网络都没办法同时实现2D转3D、在还原场景的同时还能包含清晰的语义。即使有两个网络也实现了3种方法,他们也采用了深度和边界框两种参数进行监督,而非完全通过自监督进行模型学习。
这一方法,让模型在不同的数据集上都取得了不错的效果。
无论是椅子、球体数据集,还是字母、光影数据集上,模型训练后生成的各视角照片都挺能打。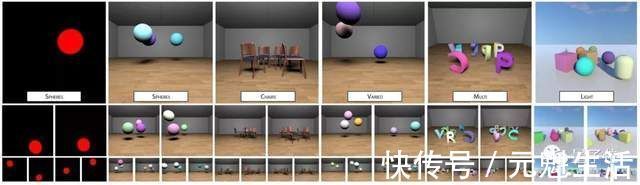
文章插图
甚至自监督的方式,还比加入5%监督(Super5)和10%监督(Super10)的效果都要更好,误差基本更低。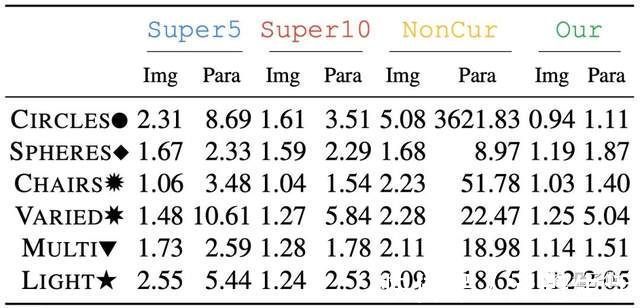
文章插图
而在真实场景上,模型也能还原出照片中的3D物体形状。例如给出一只兔子的照片,在进行自监督训练后,相比于真实照片,模型基本还原出了兔子的形状和颜色。
文章插图
不仅单个物体,场景中的多个3D物体也都能同时被还原出来。
文章插图
当然,这也离不开“好奇心驱动”这种方法的帮助。事实上,仅仅是增加“好奇心驱动”这一部分,就能降低不少参数错误率,原模型(NonCur)与加入好奇心驱动的模型(Our)在不同数据集上相比,错误率平均要高出10%以上。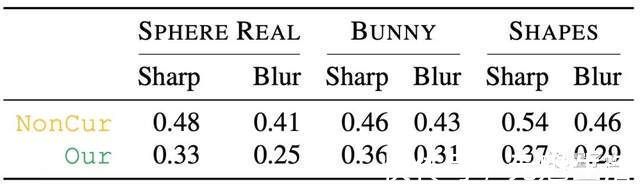
文章插图
不需要任何外部标记,这一模型利用几张照片,就能生成3D关系、还原场景。作者介绍
3位作者都来自伦敦大学学院。
文章插图
一作David Griffiths,目前在UCL读博,研究着眼于开发深度学习模型以了解3D场景,兴趣方向是计算机视觉、机器学习和摄影测量,以及这几个学科的交叉点。
文章插图
Jan Boehm,UCL副教授,主要研究方向是摄影测量、图像理解和机器人技术。Tobias Ritschel,UCL计算机图形学教授,研究方向主要是图像感知、非物理图形学、数据驱动图形学,以及交互式全局光照明算法。
有了这篇论文,设计师出门拍照的话,还能顺便完成3D作业?
- 物体做曲线运动时法向加速度有可能为0吗?
- 为什么温度高到一定程度的物体,就会发光?
- 量子纠缠存在于任何维度空间?人类如何逃出三维空间变成“神”?
- 金字塔是利用声音建造的?声波能使物体悬浮?或是外星高科技手段
- 恐惧的真相:宇宙其实是个生物体
- 旗舰机|旗舰机的更新对于任何一家厂商都没有难度,但入门级,还得看绿厂
- 矽源特NS4215是超低 EMI无需滤波器每声道输出7.5W的D类立体声音频功率放大器
- 这种生物97%都是水,没有任何营养,在海洋中却十分抢手
- Windows|如何把系统装在U盘里,任何一台电脑都可以使用自己系统?
- 漏看微信不用怕!这款神器能看到对方撤回信息,一键安装无需授权